

Throughout our lifetime, humans perform innumerable actions and make instantaneous decisions; most of them are involuntary. When you look at a unique bird, your brain instantly recognizes it as a bird, even though you might have never seen that species before. We can have conversations that we have never had before. Similarly, we know a dangerous object when we see one, even though no one has explicitly told us about it.
Learning is ingrained in our biology. Through millions of years of evolution, humans have developed to learn throughout their life. While learning comes so naturally to us, it is hard to imbed this process in a machine or an algorithm. But it is possible. Below, we break down the 14 ways we can teach machines to learn.

Types of Learning
We can categorize how machines learn into four main types:
Learning Problems
Supervised Learning #1
Supervised Learning is a field of machine learning where the algorithm learns patterns from the data by mapping pre-defined outputs to example inputs. We use labelled data (expected outcome) to train the model. For example, to train an algorithm that can differentiate between cat and dog images, we would show it explicitly labelled images of canines and felines. Supervised Learning can either categorize objects like the example discussed above or predict distinct numerical values, like the amount of rainfall a city will get on a particular day.
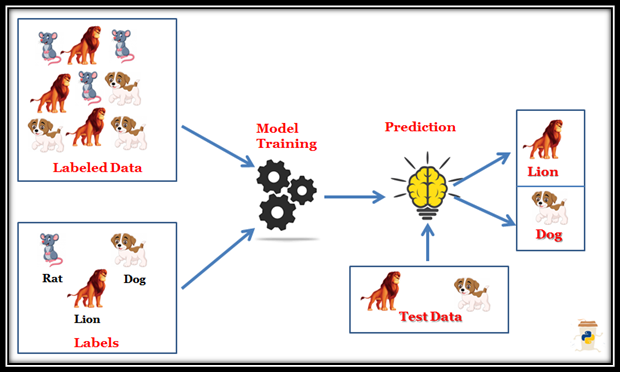
Because of the curation of massive datasets like Imagenet and extensive research on new and better algorithms, supervised learning is the most successful sub-field of Machine Learning (ML). But supervised learning comes with its drawbacks. Labelling is a time and resource-consuming task; thus, most of the data available out there will not be labelled. With supervised learning, we are only harnessing a small fraction of the true potential of the data available to us.
Unsupervised Learning #2
To overcome the limitations of supervised learning, we have unsupervised learning. There is no supervision provided; thus, the algorithm must learn to self-discover any naturally occurring pattern in the dataset. One well-known example of this is clustering algorithms, where given a dataset, an algorithm makes groups or clusters of training examples such that examples with similar features would lie in the same group.
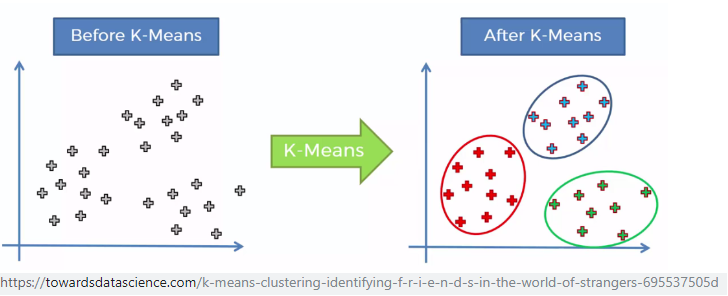
Although unsupervised learning algorithms have a massive advantage over supervised learning algorithms because it doesn’t need a considerable amount of expert human labor, there is a cost. The algorithms in this field are not as sophisticated and either take a long time to converge on an acceptable result or won’t converge at all.
Reinforcement Learning (RL) #3
Besides supervised and unsupervised learning, RL is one of the three basic paradigms of Machine Learning. In RL, the agent learns in an interactive and potentially complex environment by trial and error while taking feedback from its own actions and experiences. We reward or penalize it based on whether its actions help achieve the end goal. This is like how a toddler learns to walk in the world or how a dog is trained.
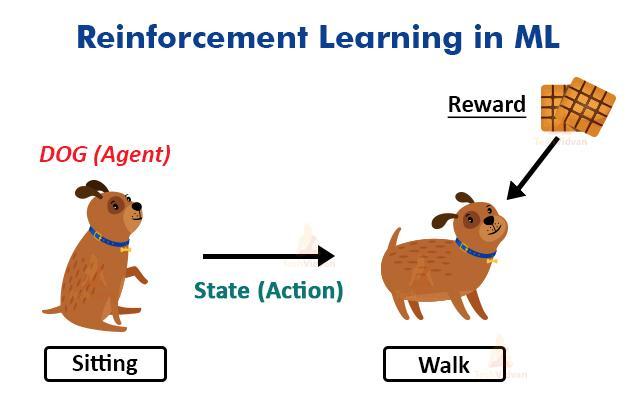
To perform this task of maximizing reward, an agent starts from totally random trials and eventually learns to navigate in the environment sophisticatedly. During learning, we deal with a Multi-armed bandit problem where there is a need to find a balance between exploring unfamiliar territory and exploiting the current one.
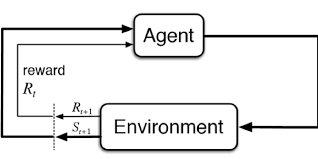
RL is modelled as a Markov Decision Process, where:
- E - the environment, specified as a state of rules that describes what the agent observes.
- St - the states of the agent
- The probability of transition from state St to St+1 because of action At.Rt- the reward/penalty after a transition from state St to St+1 because of action At.
- Rt- the reward/penalty after a transition from state St to St+1 because of action At.
Hybrid Learning Problems
The gap between supervised and unsupervised learning is significant, and many algorithms fall in the middle and draw from both techniques.
Semi-supervised Learning #4
Semi-supervised learning provides us with the best of both worlds. It offers weak supervision by combining a small quantity of labelled data with many unlabeled data while training. Semi-supervised learning is beneficial where we don’t have enough labelled data for supervised learning. For example, in a fraud detection case, you have a few labelled instances of fraud. This can train a supervised algorithm that can later label many unlabeled fraud data. This technique can be helpful when labelling is expensive or challenging, and a supervised problem has to be solved.
Self-Supervised Learning #5
Like semi-supervised learning, self-supervised learning also falls between supervised and unsupervised, but contrary to semi-supervised learning, here, you do not need even small amounts of labelled data. Instead, these learning algorithms rely on supervisory signals from the input data by leveraging the underlying structure. The general goal is to predict unobserved or hidden parts of the data.
This technique is instrumental in language models pre-trained from large amounts of un-labelled data by training them to perform a cloze test. A cloze test is basically “fill in the blanks”, where different words of the text are hidden through various iterations, and we make the model predict them. This enables the language model to understand context and vocabulary.
Multi-Instance Learning #6
Here, instead of labelling individual instances, we label groups or bags of instances. A given instance could be present multiple times. The modelling algorithm uses the knowledge that one or more instances in the group might be associated with the target label. The model learns to predict a label for unknown groups in the future, despite the noisy composition of each group.
Imagine a group of people, and each of them has a key chain that contains a few keys. Because of the different keys, some of these people can enter a specific room, and some aren’t. The task is to predict whether a particular key or a certain key chain can get you into a particular room. To solve this problem, we first need to find the exact key that is common for all the “positive” keychains. Then, if we can identify this key correctly, we can also correctly classify the entire keychain - positive if it contains the required key or negative if it doesn't.
Statistical Inference
Statistical inference involves using data to infer the properties of a population, to conclude or decide.
Inductive Learning #7
Here, the learning algorithm infers rules or patterns from the data given examples. Then, the model uses specific cases from the dataset to determine general outcomes. Most machine learning models out there inherently use this inductive reasoning to make a model of the world. Finally, a hypothesis is made about the model (the mapping function) using the training data, and we assume the inferred hypothesis would hold true for new unseen data.
Deductive Learning #8
In deductive learning, you have a general model of the world or your hypothesis, and you use this to determine specific outcomes. In machine learning, where inductive learning ends, inductive learning starts. After the model or mapping has been formed from the training data, the model has learned a set of rules to predict outcomes of specific examples.
Transductive Learning #9
Transductive learning involves reasoning from observed specific training cases to specific test cases. In machine learning, we expose both training and testing data to the model in the learning phase itself. The model here tries to find any information about the pattern in the combined dataset (training + testing) and later on uses this information for predicting the values of the un-labelled testing data points.
Unlike induction, generalization isn’t required; instead, specific examples are used directly. As a result, this may be a more straightforward problem to solve than induction.
Learning Techniques
Let’s look at some of the most common learning techniques
Multi-task Learning #10
The multiple learning tasks are solved simultaneously by leveraging commonalities and differences using the multi-task learning technique. Thus, multi-task learning could lead to better learning efficiency and improved performance when compared to a model trained on individual tasks. Multi-task learning is helpful because the regularization induced by requiring an algorithm to perform well on a related job can be superior to the regularization that prevents overfitting by penalizing all complexity uniformly.
Consider the example of a spam filter, which can be treated as a distinct but related classification task across multiple users. Different people might have different definitions of spam. For example, we might consider Russian emails spam as English speakers, while the same will not be valid for someone who speaks Russian. However, we all will regard emails related to “winning lotteries” as spam despite different primary languages.
Active Learning #11
Active Learning has been instrumental when labels are complex, time-consuming or expensive to collect. Here, the learning algorithm is allowed to proactively select a subset from the available un-labelled examples to be labelled next. The primary belief behind this type of learning is that an ML algorithm might achieve better performance even while using fewer training labels if it could choose the data it wants to learn from. In addition, we allow active learners to dynamically pose queries during the training process, usually in unlabeled data instances to be labelled by a human annotator. Again, this keeps a human in the loop.
Online Learning #12
Online Learning was born out of the need to update models frequently as the data distribution changed. Instead of learning from the entire training set at once, like in batch learning, data becomes available in sequential order and is used to update the model at each step while predicting. One example of this is stock price prediction. We train a new stock model every day by adding the last day’s stock prices to predict the stock price.
Transfer Learning #13
In transfer learning, a model trained on a particular task is either used or with some minor changes (called fine-tuning) to make predictions on a related task. Transfer Learning is especially useful when two tasks are related, and the task for which the trained model is transferring its knowledge has a small amount of data.
For example, the CIFAR-10 dataset has ten common classes like dogs, horses, cars, trucks, etc. A model trained on this could be fine-tuned to predict bananas in images, even though CIFAR-10 didn’t have any banana images. This works as the initial layers of the neural network learn abstract features like edges, contours, colors, etc. It is only in the last layers that the model learns to detect the specific features of the object itself.
Ensemble Learning #14
Here, we train two or more models on a dataset and combine their predictions during inference. Ensembles perform better than individual models because they reduce variance and increase regularization through combination, two significant problems associated with unique ML models. Ensembles also yield better results when there is a substantial diversity among the models. Based on how we combine the models, there are three different ensembling methods:
- Bagging: The predictions of independently trained individual models are averaged during prediction.
- Boosting: This is done sequentially where the performance of the last model is used to tweak the hyper-parameters of the next model to be trained.
- Stacking: Here, the output of one model is fed as input to the next one.

Conclusion
We hoped you enjoyed this overview of the different ways machines learn! If you have questions or would like to connect with the author, please drop us a line at support@refocusai.com.




